We could fit a classification model that uses average points per game and division level as explanatory variables and “drafted” as the response variable. For this type of algorithm’s predicted data, belongs to the category of discrete values. Let us understand this better by seeing an example, assume we are training the model to predict if a person is having cancer or not based on some features.
Longitudinal lung cancer prediction convolutional neural network … – Nature.com
Longitudinal lung cancer prediction convolutional neural network ….
Posted: Sat, 15 Apr 2023 12:47:41 GMT [source]
K nearest neighbour is a good example where the task and the method are both called classification. Regression and classification can work on some common problems where the response variable is respectively continuous and ordinal. The higher that number, the better because the algorithm predicts correctly more often.
In data mining, there are two major predication problems, namely, classification and regression. The most basic difference between classification and regression is that classification algorithms are used to analyze discrete values, whereas regression algorithms analyze continuous real values. Supervised learning has been helpful in several biometric apps with the help of classification algorithms.
Average recognition results accuracies, sensitivities and specificities using regression and classification model and sensor combinations. This study is based on publicly open data set called AffectiveROAD . It contains data from nine participants measured using Empatica E4 wrist-worn device . However, three participants performed data gathering session more than one’s, and therefore, the dataset contains data from 13 data gathering sessions. E4 includes accelerometers , as well as, sensors to measure skin temperature , electrodermal activity , blood volume pulse , heart rate , and heart rate variability .
Sign Up for FREE Machine Learning Tutorials
Regression and classification are categorized under the same umbrella of supervised machine learning. Both share the same concept of utilizing known datasets to make predictions. Classification algorithm classifies the required data set into one or more labels; an algorithm that deals with two classes or categories is known as a binary classifier.

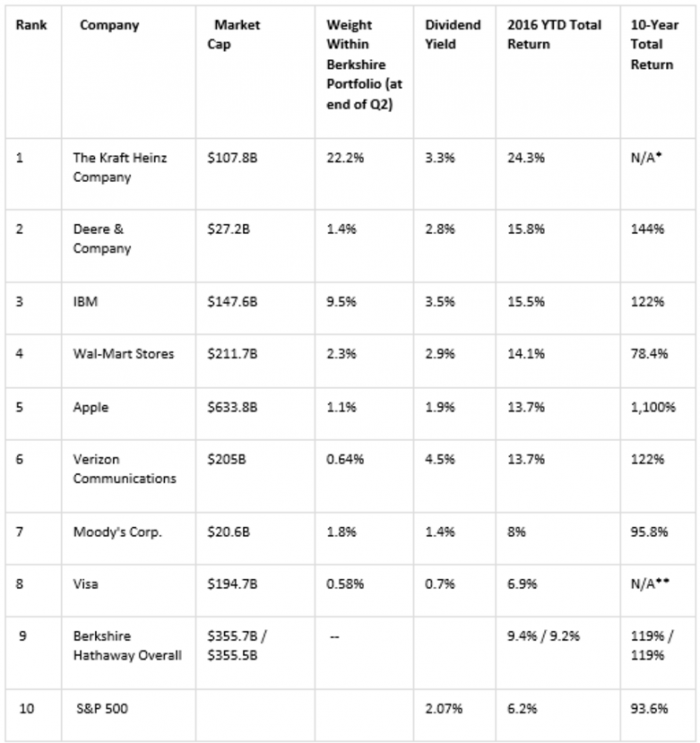
With this setting, the average balanced accuracy was 74.1% with classification model and 82.3% using regression model. In addition, sensitivity and specificity values are the highest using this combination. Confusion matrix for regression model for regression model using these features is shown in Table 3, where it can be seen that both classes are detected with reasonable accuracy. Another reason for it is that regression models gets more information as an input than classification model. In fact, classification models gets binary class labels as input while regression model’s inputs are continuous targets.
Table 3
Are used when the dataset needs to be split into classes that belong to the response variable. To answer this question, first, let us understand classification and regression using the below diagram. Learning to spot where regression and classification overlap is vital for determining which is the right model for solving a given problem. Classification involves predicting discrete categories or classes. An example of a regression problem would be determining the price of food crates based on factors like the quality of the contents, supply chain efficiency, customer demand, and previous pricing. In short, the outcome variable doesn’t fit into discrete categories.

These exceptions suggest that stress does not cause similar reactions to every person. Moreover, Figure 1 shows the personal threshold used to divide regression model outputs as stressed and non-stressed . In most cases, the value of this threshold is between 0.3 and 0.5. In the case of MT, the value of threshold is close to 1, and in the case of SJ, the value is close to 0. This underlines how special these the cases are compared to other seven study subjects. One area where these skills come in particularly useful is in the field of predictive analytics.
Suppose we want to do weather forecasting, so for this, we will use the Regression algorithm. In weather prediction, the model is trained on the past data, and once the training is completed, it can easily predict the weather for future days. Regression is a prediction method that is based on an assumed or known numerical output value. This output value is the result of a series of recursive partitioning, with every step having one numerical value and another group of dependent variables that branch out to another pair such as this.
Keras vs Tensorflow vs Pytorch: Understanding the Most Popular Deep Learning Frameworks
In this blog, we will understand the difference between regression and classification algorithms. The main advantage of using regression models is that they can not only be used to recognize whether the person is stressed or not, they can also be used to predict the level of the stress. However, based on our experiments this prediction is not very accurate, and for some study subjects it does not work at all. In fact, the main goal of the future work is to study how the quality of this prediction could be improved. Due to this, different regression models needs to be compared to find out which is the most capable to predict the level of the stress.
Machine Learning vs. Deep Learning vs. Neural Networks – IoT For All
Machine Learning vs. Deep Learning vs. Neural Networks.
Posted: Tue, 18 Apr 2023 10:00:00 GMT [source]
A classification tree splits the dataset based on the homogeneity of data. Say, for instance, there are two variables; salary and location; which determine whether or not a candidate will accept a job offer. It works by splitting the data up in a tree-like pattern into smaller and smaller subsets. Then, when predicting the output value of a set of features, it will predict the output based on the subset that the set of features falls into. Such a simple decision-making is also possible with decision trees.
Likewise, regression algorithms can sometimes output discrete values in the form of integers. What’s more, a classification algorithm can sometimes output contiguous values, if these values are in the form of a probability that the data fall into a particular category. For example, if based on the data you have there’s a 34.6% chance that the vegetable you’re identifying is a carrot, this is still a classification problem despite having a contiguous figure as its output.
However, both areas are incredibly complex and take time and effort to understand better. Subject-wise RMSE and R-Squared using user-independent model and a combination of BVP and ST features. A regression algorithm can help retailers analyze customer behavior to determine the peak times when customers visit the shop.
Is Decision Tree a classification or regression model?
If you take the student example from above, a classification algorithm would predict if a student will pass or fail an exam, while a regression algorithm would predict the percentage mark they receive. The decision tree models can be applied to all those data which contains numerical features and categorical features. Decision trees are good at capturing non-linear interaction between the features and the target variable. Decision trees somewhat match human-level thinking so it’s very intuitive to understand the data.
Machine learning classification algorithms can be used in different scenarios—here are a few of the most popular use cases. This algorithm analyzes the independent variables to determine which of the two categories the outcome falls into. BUT, when we actually use logistic regression, we almost always use it as a classifier. Let’s say that you want make a model that predicts whether a person will buy a particular product.
To visualize the performance of the multi-class classification model, we use the AUC-ROC Curve. It is a graph that shows the performance of the classification model at different thresholds. Unlock the untapped potential of your data and revolutionize decision-making with our intelligent analytics. Our experts can give you unique insights to supercharge growth, increase efficiency, optimize experiences, and reduce costs – whatever it takes for your business success. To build a decision tree requires some data preparation from the user but normalization of data is not required.
The value of log loss increases if the predicted value deviates from the actual value. For a good binary Classification model, the value of log loss should be near to 0. When expanded it provides a list of search options that will switch the search inputs to match the current selection.
Regression vs Classification, a Quick Introduction
If the training data shows that 95% of people accept the job offer based on salary, the data gets split there and salary becomes a top node in the tree. Measures of impurity like entropy are used to quantify the homogeneity of the data when it comes to classification trees. Learning to spot these subtle similarities between classification and regression is key to choosing the right model for the problem you’re trying to solve. We strongly encourage you to familiarize yourself more with both types of problems by reading about the topic.
- When we do supervised learning, we use a machine learning algorithm to build a machine learning model.
- Of course, transforming continuous phenomenon as discrete is far from optimal solution, and this type of problem simplification can cause problems in the modelling phase.
- Adecision treeis fundamentally a flow-chart which resembles a tree structure where each internal node depicts a test on an attribute, and its branches shows the outcome of the test.
- Hernandez J., Morris R.R., Picard R.W. Call center stress recognition with person-specific models; Proceedings of the International Conference on Affective Computing and Intelligent Interaction; Memphis, TN, USA.
- When we use classification, we feed training data into a machine learning algorithm.
- For classification model, target values were transformed as 1 and 0, so that data from baseline are labelled as 0 and data from driving as 1.
Another study, where continuous target values for stress detection were gathered is . Furthermore, in the study concentrates on analyzing stress while driving, and during the data gathering, driver constantly estimated his/her own stress level. However, while in these two datasets the data contains continuous target values, in both cases the final analysis is based on discrete targets created based on continuous targets. On the other hand, there is also studies where stress and other affective states have analyzed using regression model (see for instance ; however, these are rare compared to studied based on classification methods.
We see more robots, self-driving cars, and intelligent application bots performing increasingly complex tasks every day. This image, courtesy of Javatpoint, illustrates Classification versus Regression algorithms. Let’s take a similar example in regression too, where we are finding the probability of rainfall in some specific regions with the aid of some parameters reported earlier.
In addition to E4 data, AffectiveROAD includes data from Zephyr Bioharness 3.0 chest belt. However, in this study, only Empatica E4 data are used as the focus of this article is in wrist-worn sensors. Moreover, to be able to better compare the results of the study to the results of previous studies, only data from right wrist-worn Empatica was used.
More practically, it indicates the strength of the relationship between one https://forexhero.info/ numerical variable and one or more other numeric variables. They struggle to understand the differences between regression and classification problems. I’m thinking this is my fault as an instructor, so I want to clarify these differences the best I can, in as brief a way as possible. As a data scientist, you need to know how to differentiate between regression predictive models and classification predictive models so that you can choose the best one for your specific use case. Unfortunately, there is where the similarity between regression versus classification machine learning ends.
- However, the Classification model will also predict a continuous value that is the probability of happening the event belonging to that respective output class.
- Both use one or more explanatory variables to build models to predict some response.
- This is fundamentally different than a regression problem where the target is a continuous number.
- The decision tree models can be applied to all those data which contains numerical features and categorical features.
- This image, courtesy of Javatpoint, illustrates Classification versus Regression algorithms.
When we use classification, we feed training data into a machine learning algorithm. As I just mentioned, regression and classification are both types of machine learning tasks. Another problem is that you cannot always easily distinguish regression and classification problems based on their input data. For instance, whether or not you have a regression or a classification task, the input data can either be discrete (e.g. sorted into categories or classes) or continuous (e.g. quantities). Predictive analytics is an area of data analytics that uses existing information to predict future trends or behaviors. This type of analysis applies to many areas of data analytics, but it is particularly prominent in the emerging fields of artificial intelligence and machine learning.
A simple example of a difference between regression and classification problem in predictive analytics would be sorting a dataset of vegetables by color, based on their size, shape, and name. While there are several categories you can use, e.g. red, green, orange there will always be a finite number of them to choose from. The results (i.e., predictions) that come from these algorithms is a value, one in the list of possible values for the categorical variable. This is fundamentally different than a regression problem where the target is a continuous number. The way we measure the accuracy of regression and classification models differs.
However, stress and other emotions are not discrete phenomenons as for instance the level of the stress of a person can be high or low or anything between these. In , it was suggested that discrete classification results could be transformed as continuous based on posterior values. Thus, still also in this case, the original classification to stress/non-stressed would be based on discrete target values. Of course, transforming continuous phenomenon as discrete is far from optimal solution, and this type of problem simplification can cause problems in the modelling phase. In fact, this means that a problem that originally was regression problem is transformed as classification problem. Therefore, a better option would be to base stress and affect detection to continuous target values.